Hey Hey,
For the first part we will take a look at why, PART 2 will be having a look at a simple implementation with services available to download.
So As Ive mentioned before for the last 14 months I have been doing nothing but PaaS (Platform as a Service) at a very large scale, with continuous development and continuous integration in mind. Over this time Myself and the people I work with have been constantly refining deployments adding more and more.
For the most part the entire VMware stack is being used this includes vRO, vRA including Application services and code stream.
Bascially:
vRA provides IaaS
App Services provides the PaaS
Codestream provides the CI integration
and vRO does everything inbetween
One of the challenges put forward by the client was to limit the end user input as much as possible, early on there was alot of fat finger errors or things like VIP DNS names being inconstant. Out of this issue what I will refer to as the PaaS ID and the use of key value store was born.
First of, what do I mean by PaaS ID? In reality its just a unique ID but done in a way that majority of the user inputs can be derived, but at the same time be unique. For a App services deployment this would be the only input required by the end user and would be formatted similar to this:
<project code>.<release>.<environment>.<product>.<product ID>.<Instance ID>
Product ID is the only field that can be blank and we would get a PaaSID similar to this:
CAG.R001.DEV.IIS..i01 or CAG.R001.DEV.SOA.ENT.i01
This allows the creation of PaaS inputs in a constant manner every time for example:
F5 loadbalancer name to be created like IIS-DEV-CAG011.virtualiseme.net.au
Service Accounts like SYS-CAG001-DEV-IIS@virtualiseme.net.au
weblogic domain like CAG01-SOA-ENT-DEV
Can put together alot of different inputs required like database tables, database name and a number or different application inputs this gives a consistent development and support environment across all the products and environments. and very easy to report on.
So the PaaS ID took care of the initial deployment in regards to inputs but what about day 2 operations.
During the 14 months and counting more and more day 2 actions are being used and developed.
For those new to this day 2 operations are actions performed on a machine or a bunch of machines after they have been deployed.
vRA provides some of these out of the box, the simple ones being shutdown, power on reconfigure etc.
But for full multi tiered multi clustered environment these could be application specific actions like in the case or weblogic configuring a domain and adding a data source etc, wanting to add additional load balancer configurations, or creating a website etc.
All of these actions were possible but required alot of input which could result in incorrect configuration or making the configuration on the wrong deployment.
Some information can be programmatically pulled out from App Service and vRA but not everything, ETCD to the rescue!!!
So any key value store can be used as log as it got some type of rest API, etcd is the one Ive been using and find it really basic to use yet its distributed and highly available so can be used in an enterprise configuration.
So what does this mean? when we input the PaaS ID it will create the PaaS ID as the root folder for the deployment and add in any keys that the PaaS ID has generated for the deployment. Then in the application scripts or dedicated services we add in all the details we want or need into the key value store under that initial PaaSID folder. To keep it clean and simple the use of folders are used under the paasid like passwords or nodes or database, containing all the keys and values for specific details of a deployment.
The image below shows a Oracle SOA deployment with the specific services that add in details to ETCD. In the image below the PaaS Interprete service supplies the load balancer name, Welblogic domain name, DNS CName format, where to place password and accounts created in secret server, what puppet groups the servers belong to.

The images below show a quick look at how the data is sitting with ETCD. when calling via rest the format back is JSON.

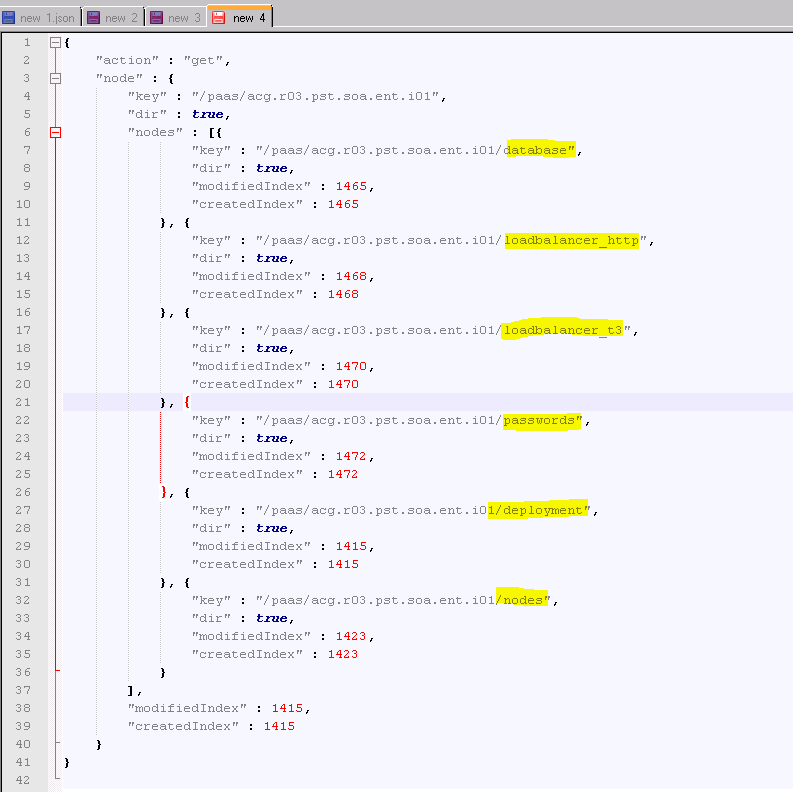
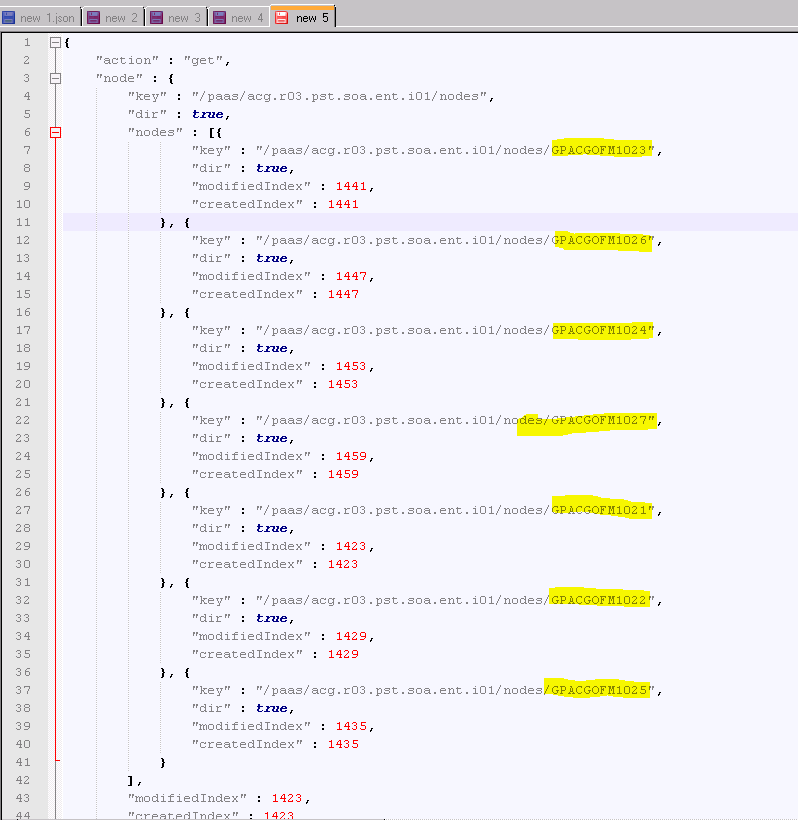

Just by the above images you can see how much data we can fit into ETCD and being java it works great in vRO with is all java based and traversing and gather keys is very easy within javascript.
So now we have data in the Key value store whats an example of using it?
So one of my customers has a concept of Levels so they want automation to be used across projects so we have a level system. this happens to work for this customer and can very but essentially
layer 1 – Physcial tin
Layer 2 – Hypervisor and VMs
Layer 3 – Application deployed in vanilla ootb state
Layer 4 – Project specific Application configuration
Layer 5 – custom code deployment
So when the end user provisions a say a SOA/OSB environment it will provision to layer 3. They then have a day 2 action within vCAC to configure layer 4. We are able to do this by using the PaaS ID and the data within the Key Value Store being ETCD with out a bit of data entry for the end consumer
The below image is an example of a configuration task which requires no input by the end user.


The workflow behind this is as below:
· takes internal vRA deployment ID and match to AppD deployment ID
· using the AppD deployment ID find the Last task ID for that deployment
· Using the task ID get the entire deployment services and properties
· Search for the Unique ID
· Take the ID and look in KVS to see if Layer 4 has been run (in this case layer 4 is environment specific configuration of the application and don’t want it run twice)
· Get all the servers that are a part of that application
· Find the admin node based on a key nodetype
· Get the vCenter Objects take a snapshot of all the VMs
· Query secret server for the admin root password using the secretID in KVS under the Admin node.
· Get the deployment information in this instance MyST ID so correct configuration is run over the deployment
· Run the configuration script on the admin node using run script in guest
· Add key and value for completing layer 4 task so it can’t be accidentally re run.

Some additional use cases for the use of a key value store with vRA are:
1) Orchestrate timings and events
Using ETCD we can wait for key changes using a long poll, this can help with dependencies being able to make simpler scripts that can wait for other nodes to finish tasks,
2) Tying Deployments together
SOA or OSB deployment requires the database details of say an OPA deployment, or BIP deployment requires Siebel deployment to intergrate with. Using the KVS and ID’s we are easy able to incorporate these operations in a day 2 configuration action without the need to any data input, also being able to build property files when needed.
3) Embedding scripts by using base64 encoding. Instead of an “admin” server copying a file out to all the servers in the cluster or platform, it can post the file as a value in the KVS and all other nodes grab it from there then deencode and run the script. This is handy with web to app servers as you don’t require the ports to be open to copy files and content between the tiers.
Next in part 2 we will have a look at a simple deployment of etcd using the nanotrader application
Cheers
[…] has been great feed back from part 1 of this series, this part will carry on and extend Part […]
[…] further we can store the secret ID like mentioned in Extending vRA with ETCD posts THERE, we can grab the password pragmatically for day 2 actions without the end user ever needing to know […]
[…] further we can store the secret ID like mentioned in Extending vRA with ETCD posts HERE, we can grab the password pragmatically for day 2 actions without the end user ever needing to know […]
[…] further we can store the secret ID like mentioned in Extending vRA with ETCD posts HERE, we can grab the password pragmatically for day 2 actions without the end user ever needing to know […]
[…] further we can store the secret ID as mentioned in Extending vRA with ETCD posts, and grab the password pragmatically for day 2 actions without the end-user ever needing to know […]